Research content
Step 1.1
Obtain the optimal pH value and sequence of bacteria based on big data
The data of the optimal pH value for bacterial growth and the corresponding genomic or 16S rRNA sequences will be obtained from public databases such as BacDive and literature reports.
Step 1.2
Obtain the genomic characteristics of bacteria based on bioinformatics methods
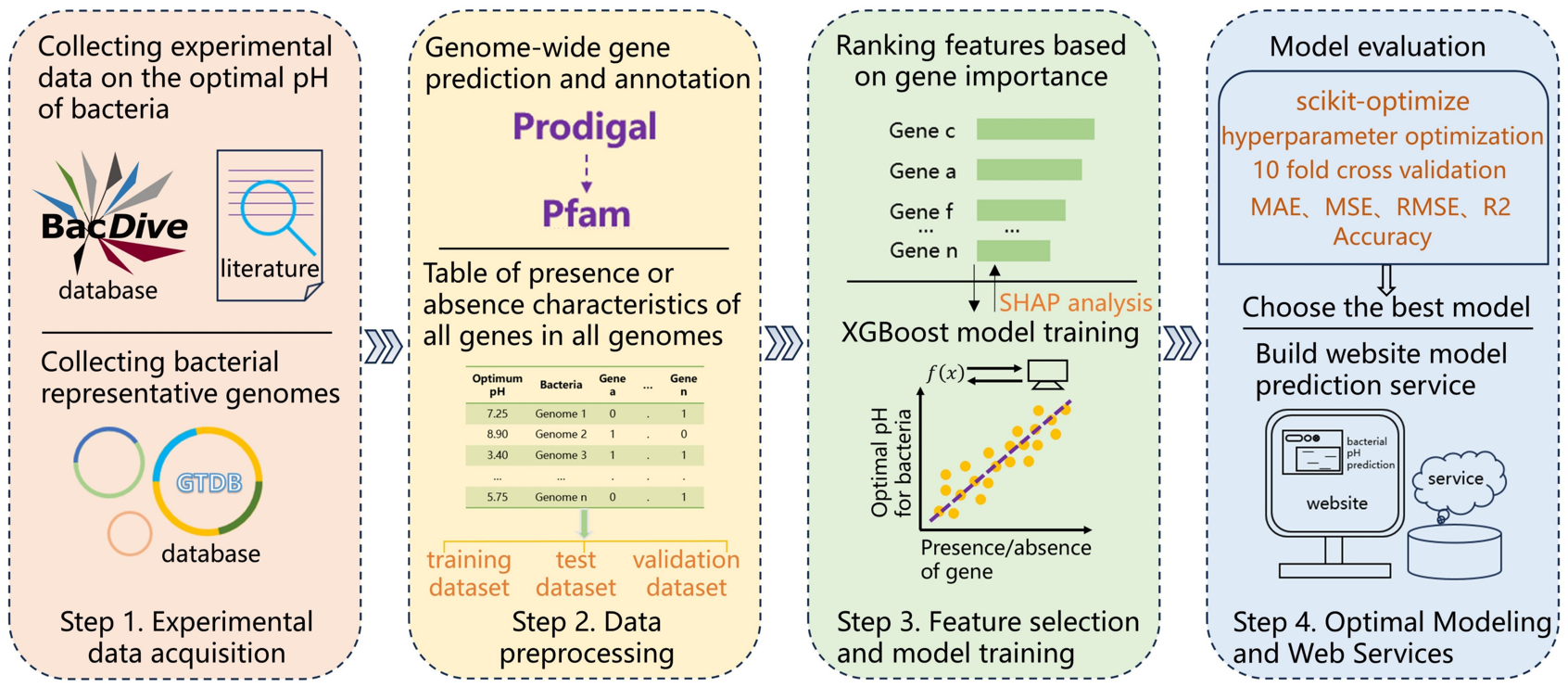
If the sequence representing bacteria in the collected data is the 16S rRNA sequence, the corresponding bacterial genome sequence will be matched through the bioinformatics method of sequence similarity matching. After obtaining the representative genomic sequences of all bacteria, all gene types existing in the bacterial genomes were predicted through bioinformatics tools such as Prodigal. Then, the genes related to bacterial pH preferences reported in the literature were combined to obtain the presence or absence characteristics of PH-related genes in the bacterial genomes. Subsequently, other genomic characteristics such as tRNA, rRNA, and ORF in the bacterial genome were also predicted.
Step 1.3
Build a precise prediction model through machine learning methods
Based on the characteristics of the bacterial genome with the known optimal pH value obtained from the content of 2.2, important features that can be used for machine training are obtained through methods such as feature selection and multi-feature fusion. Models are constructed through machine learning methods such as XGBoost, logistic regression, and support vector machine. Models are evaluated and compared using criteria such as five-fold cross-validation, model accuracy, and sensitivity to find the best parameters and models.
Step 1.4
Isolation and culture of silage bacteria and determination of their optimal growth pH value
By equipping with appropriate culture media, such as ordinary broth, nutrient AGAR, etc. Adjust the pH value of the culture medium as needed. Inoculate the bacteria to be tested into the culture medium, set different experimental pH gradients, and observe the growth of the bacteria at each pH value. Including colony count, growth rate, etc. Based on the recorded data, draw the growth curve graph between bacterial growth and pH value. Based on the growth curve graph, determine the most suitable pH value for bacterial growth.
Step 1.5
Build a platform for accurately predicting the optimal pH value for bacterial growth
If the optimal pH value for bacterial growth determined in the experiment is consistent with the results predicted by the model, it once again proves that the constructed model is accurate. Then, Python programming is utilized to build the public platform, including the website and software for predicting the optimal pH value for bacterial growth.
First, attempt the feature of the presence or absence of a common key gene. Use the XGBoost algorithm to construct a basic model based on the final split training set using Python programming. Then, use the SHAP method to explain the model (" black box ") to determine which core genes in the whole can significantly affect the prediction of the model. Then, feature selection is carried out based on feature importance analysis methods such as permutation and gain to find genes related to the optimal pH for bacterial growth. Based on these found characteristic genes, the corresponding datasets were programmed and extracted, and the XGBoost algorithm was reused to construct the model. Then, indicators such as five-fold cross-validation, Jackknife validation, accuracy, recall rate, F1 score, area under the ROC curve, root mean square error, and Matthews correlation coefficient were conducted to evaluate the model. During this period, parameters were adjusted repeatedly until the optimal hyperparameters were found. Next, the same steps are used to build models for other algorithms such as logistic regression, support vector machine, random forest, K-nearest neighbor algorithm, and backpropagation neural network. Finally, make mutual combinations and comparisons. Select the best model (preferably considering the one with the highest accuracy index value).
Step 2
The proposed research methods and experimental plans
Step 2.1
Obtain the optimal pH value and sequence of bacteria based on big data
Data on the experimentally determined optimal pH values for bacterial growth were obtained from databases such as BacDive (https://bacdive.dsmz.de/); Then, From PubMed (https://pubmed.ncbi.nlm.nih.gov/), Google scholar (https://scholar.google.com/), a Web of Science (https://webofscience.clarivate.cn/wos/woscc/basic-search), China hownet (https://www.cnki.net/) and other literature database, by keywords, For example, keywords such as "Bacteria*", "Growth", "Optim**", "pH", "bacteria", and "pH" in both Chinese and English, as well as regular expression methods, have yielded a large number of experimentally determined optimal pH values for bacterial growth. According to obtain the bacterial species, Latin name from GTDB (https://gtdb.ecogenomic.org/), NCBI (https://www.ncbi.nlm.nih.gov/), IMG (https://img.jgi.doe.gov/faq.html Bacterial genome sequences or 16S rRNA sequences were obtained from databases such as silva (https://www.arb-silva.de/).
Step 2.2
Obtain bacterial genomic characteristics based on bioinformatics methods
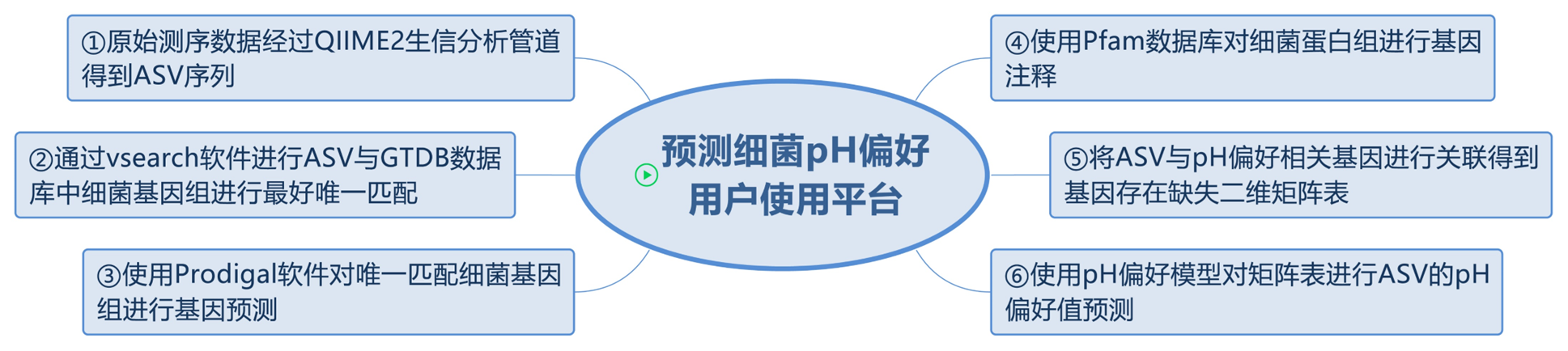
If the sequence representing bacteria in the collected sequence data is the 16S rRNA sequence, the best match between the 16S rRNA sequence and the bacterial genome sequence in the GTDB database is conducted through the vsearch software to find the unique corresponding representative sequence of the bacterial genome. After obtaining the representative genomic sequences of all bacteria, all the gene sequences existing in the bacterial genomes were predicted through the Prodigal software, and then the proteomes corresponding to these genes were genetically annotated using the HMMER software. In this way, all the gene types existing in each bacterial genome are obtained. Then, the genes related to the bacterial pH environment preference reported in the literature are compared, recorded and combined. Then, through Python programming, the presence (1) or deletion (0) of all gene types are combined into a two-dimensional matrix table. After that According to the bioinformatics method published by David et al. (84), the contents of tRNA, rRNA, ORF, A+G in the bacterial genome, the fractions of codons and dinucleotides, the fraction of substitute start codons TTG, proteomic characteristics (amino acid components, charged or heat-sensitive components in the proteome, EK/QH, LK/Q, polarity/charged, pole) were predicted Other characteristics such as the ratio of hydrophobic amino acids.
Step 2.3
Build a precise prediction model through machine learning methods
The final obtained data is split. 90% is used for the training set and 10% for the validation set. Then, 90% of the training set is further split into the training set and 10% into the test set. The schematic diagram is as follows:
First, attempt the feature of the presence or absence of a common key gene. Use the XGBoost algorithm to construct a basic model based on the final split training set using Python programming. Then, use the SHAP method to explain the model (" black box ") to determine which core genes in the whole can significantly affect the prediction of the model. Then, feature selection is carried out based on feature importance analysis methods such as permutation and gain to find genes related to the optimal pH for bacterial growth. Based on these found characteristic genes, the corresponding datasets were programmed and extracted, and the XGBoost algorithm was reused to construct the model. Then, indicators such as five-fold cross-validation, Jackknife validation, accuracy, recall rate, F1 score, area under the ROC curve, root mean square error, and Matthews correlation coefficient were conducted to evaluate the model. During this period, parameters were adjusted repeatedly until the optimal hyperparameters were found. Next, the same steps are used to build models for other algorithms such as logistic regression, support vector machine, random forest, K-nearest neighbor algorithm, and backpropagation neural network. Finally, make mutual combinations and comparisons. Select the best model (preferably considering the one with the highest accuracy index value).
Step 2.4
Isolation and culture of silage bacteria and determination of their optimal growth pH value
By equipping with appropriate culture media, such as ordinary broth, nutrient AGAR, etc. Adjust the pH value of the culture medium as needed. Inoculate the bacteria to be tested into the culture medium, set different experimental pH gradients, and observe the growth of the bacteria at each pH value. Including colony count, growth rate, etc. Based on the recorded data, draw the growth curve graph between bacterial growth and pH value. Based on the curve graph, determine the most suitable pH value for bacterial growth. If the optimal pH value for bacterial growth is within a (very small) range, take the median of this range as the representative of the optimal pH value for bacterial growth.
Step 2.5
Build a platform for accurately predicting the optimal pH value for bacterial growth
The optimal model constructed through process 3.3 predicted the optimal pH value for the growth of bacteria isolated and cultured from silage samples determined in 3.4, and compared it with the optimal pH value for growth determined experimentally in 3.4. If the error is very small, it indicates that the prediction is successful. Then, using Python programming, a user-use website for predicting the optimal pH value for bacterial growth is constructed based on tools such as the Django framework, MySQL database management tools, JavaScript, HTML5, CSS, etc. A user desktop software for predicting the optimal pH value for bacterial growth is constructed based on the PySide2 framework.
Workflow for predicting the optimal pH for bacterial growth